
Programming involves an immense amount of theoretical knowledge. Understandably there can be a steep learning curve to those that are new to the field. Most technology blogs will point you to an introductory programming or scripting language to convey the basics, however they do not provide you with much information beyond that. Let us guide you into a more industry centric view of computational science and development.
Data Structures and Algorithms

What is a Data Structure and Why do we use Algorithms?
Data Structures are data organizations, managements and storage formats that enable efficient access and modifications. However data structures alone are not enough to solve complex operations in a technological society. We require a way to take specific input and produce a specific output. Algorithms, much like computation, are mathematical or textual in nature. Understanding the order of an algorithm gives you insight on the efficiency of that algorithm given a specific amount of data or input. There are a number of ways to calculate this efficiency, such as:
- Time Efficiency - a measure of the amount of time it takes for an algorithm to execute.
- Space Efficiency - a measure of the amount of memory needed for the algorithm to execute.
- Complexity Theory - a study of the performance of a specific algorithm.
- Function/Asymptotic Dominance - a rule of measure that is more commonly used in Calculus, but can provide a detailed analysis on a specific algorithm
The industry standard for computing efficiency of an Algorithm is rooted in Big(O) Notation:
Big O specifically describes the worst-case scenario, and can be used to describe the execution time required or the space used (e.g. in memory or on disk) by an algorithm.
(Rob Bell, rob-bell.com)
Data Structures and Implementation
Not all data is the same and therefore not all data structures are the same. A brief synopsis of typical data structures includes:
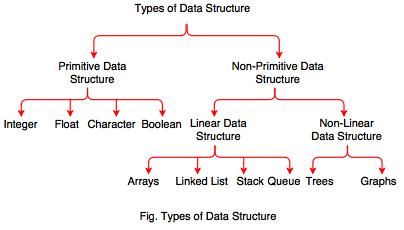
It is through these organizations of data that computer scientist can generate methodologies for searching, sorting, backtracking, branching, etc. There are instances where certain methodologies or algorithms work best with certain types of data structures, which is why it is in your best interest to learn the various types of data structures in detail as well as which data sets they are prioritized for.
Primarily most data structures are utilized in general use case scenarios, but there are a few more advanced data structures that are reserved for very specific computational task. The more common data structures that you will encounter include: Linked Lists, Queues and Stacks, Hash Tables, Heaps, Tries and Trees. Common applications of these data structures include web-browser history searches, web-browser “forward and back” functionality, language processing, CPU and Disk scheduling, network routing, spell checkers, and artificial intelligence.
There are certain scenarios that will prompt the use of a more advanced data structure, these structures include: Graphs, Disjoint Sets, or Bloom Filters. Data structures are ultimately a way to organize a given input to better direct a suspected output through the use of an algorithm. As a developer you will encounter a number of scenarios that require you to search outside of the box for a proper solution. Understanding the functionality behind these data structures will provide you with a foundation to begin the development life-cycle of said application or problem.
For a deeper understanding of these Data Structures please refer to this repository which offers detailed descriptions and examples of various data structures and their applications.

Modern Industry and Foundational Principles
Industries are not rooted in uniformity. There are standards and methodologies for doing things that will differ depending on the industry or setting that you are in. Proprietary strategies and development life cycles are abundant in a field where every organization is in competition with the next. However there is an underlying methodology for which companies design, develop and deploy software-based products and services.
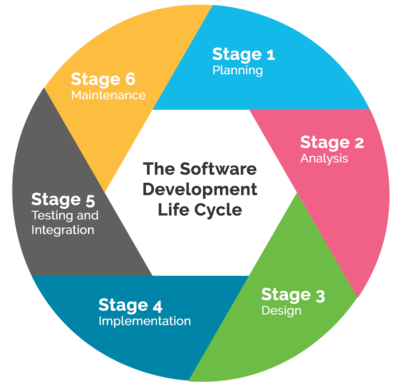
The diagram above encompasses the steps that are typically used to bring a product from idea to launch. Maintaining that workflow will be done through a software development platform like Github or Gitlab. One methodology for keeping track of development environments throughout the development life-cycle incorporates the use of a master or release environment/branch and the use of a development environment/branch:
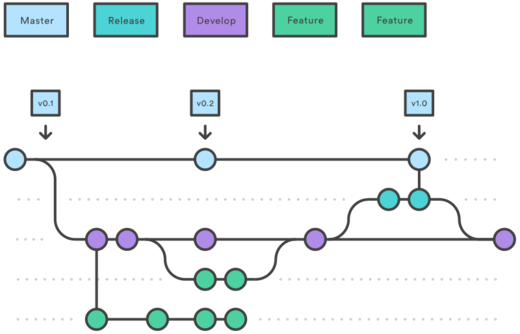
Incorporating both of these aspects into your software development practices will provide the direction necessary for you to maintain a project throughout multiple steps of the software development life cycle. Proper documentation and repository management will allow for other collaborators to quickly and efficiently navigate your open source project while at the same time make contributions on any number of issues throughout development.
- Jzbonner 🌐